Push Process
How does it work?
The PUSH process facilitates the smooth propagation of changes from the Quality Assurance (QA) environment to the Production (PROD) environment. This process involves selecting the project and objects to be propagated through a few-step procedure.
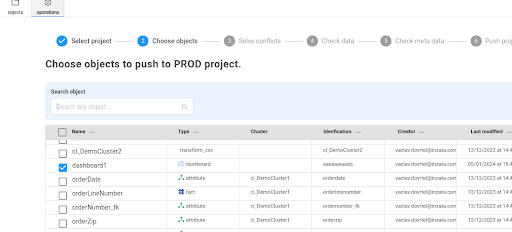
During the first and second steps of the PUSH process, users are required to choose the project and objects slated for propagation.
This marks a significant improvement from the previous version, as users are no longer obligated to be aware of all dependent objects. The system leverages the Object Dependency Model (ODM) graph, illustrated in Image 1, to identify and manage dependencies. This eliminates the need for users to manually specify all dependencies.
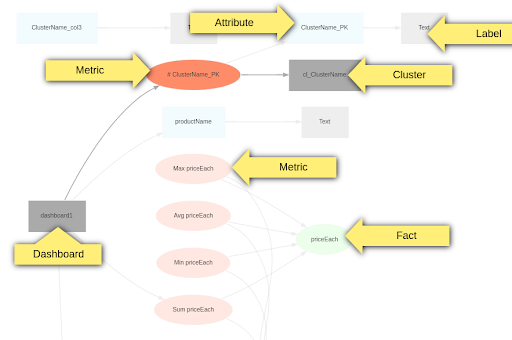
The system leverages the Object Dependency Model (ODM) graph, illustrated in Image 1, to identify and manage dependencies. This eliminates the need for users to manually specify all dependencies.
The rules for resolving dependencies are as follows:
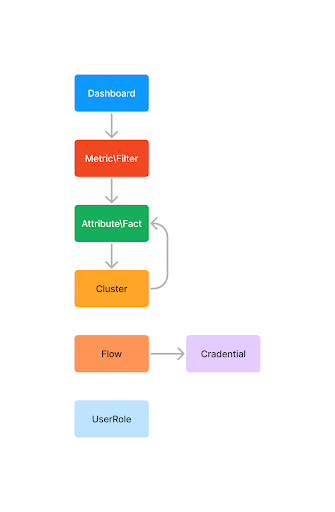
Dependency resolution relies on other dependencies, with the following exceptions:
UserRole: User role objects are not automatically marked as dependencies but can be selected in Step 2(choose object).
UserRole Users: Users within user role objects are not synchronized at all.
Cluster: Clusters are synchronized as a single object. This implies that all newly added or deleted columns will be synchronized, ensuring the cluster is identical after the synchronization process. Additionally, all dependent attributes and facts will be propagated to the target project. An attribute/fact can be deleted if the corresponding column was removed in the source project.
Cluster and Joins: Clusters are recursively synchronized with all joined clusters.
Flow: Currently, flows are not dependent on clusters or other objects and must be selected in Step 2(choose object).
Flow Credentials: Credentials are created in the target project but without content and must be set again in the target project.
WebDAV Files: All dependent files from WebDAV, including input files for inflow and images for dashboards, are ignored and must be synchronized manually.
Folder: All objects within a folder are marked as dependent for synchronization.
Market Packages: Currently, packages cannot be synchronized. This capability will be available at the beginning of February.
How to resolve conflict?
Currently, conflicts can only be resolved by rewriting the target object. This entails rewriting both the title and content. Or the second option that the input object selected in step 2 will be ignored. This step shows only objects with conflicts, not all that will be added. To show and check all changes in the target project go to next step.
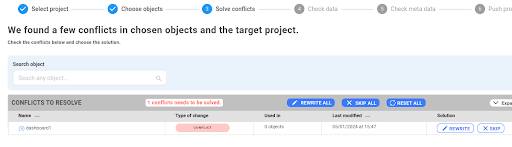
What is the “Check meta data” step?
In this step, users can check for all possible objects and data issues in the target project after the push.
If everything is ok it will show: 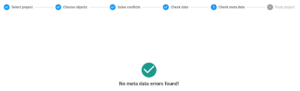
There may also be issues present in the target project before the push. Therefore, please carefully inspect the errors. If you are unsure, you can also review current issues in inModeler within the target project:
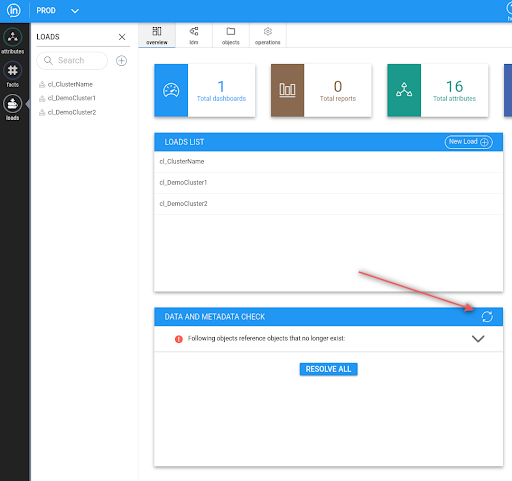
KNOWN ISSUES
- If objects has “userrole” as dependency the push fails now on “Cannot process object aaeaaaiaadq: its ACL definition points to role aafbbb1aade, which does not exist!”. Will be fixed at the end of January.
- In step 5 (check meta data) there can be an issue “Following objects have broken ODM: These objects can be regenerated.”. This issue means that the user has to go to the target project to inModeler after the push and click on resolve md issue.
WARNING: Before the resolve, check that there is only one issue “Following objects have broken ODM”.
See image:
TODO
- Ability to push dependent packages. For example, users connect “time dimension” from the market in QA and want to propagate these changes to PROD. This capability will be available at the beginning of February.
- Ability to filter objects in step2(choose object) by type, time of modifications … TBD
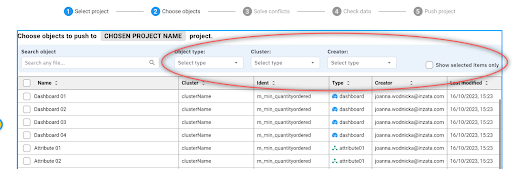
3. The capability to display differences between objects during conflict resolution. TBD
4. Mark inflows as dependent objects for clusters. Currently, inflow is not dependent on the cluster, and if the cluster is synchronized, the flow is not propagated to the target. TBD

