Creating Data Pipelines with inFlow
InFlow is Inzata’s data ingestion and application, used to create real-time data pipelines for transporting your data. Whether you want to load in a single CSV file or connect to a database, this is where you’ll start. See the inFlow Navigation to reference particular pieces of the application. InFlow can be used to create both inbound and outbound data flows, giving you maximum flexibility.
Creating a new Flow
Design tip: It is good practice to give each data source its own flow so you can schedule and execute each one individually using Triggers, however you can have multiple data sources within one flow.
To create a new flow click either of the buttons indicated with red arrows in the picture below. If there are existing data loads, you may see them listed on this page.
 Upon creating a new flow, you will see the default new flow. While you can create flows in this view, we recommend changing to a list view by toggling the button on the bottom of the right side menu.
Upon creating a new flow, you will see the default new flow. While you can create flows in this view, we recommend changing to a list view by toggling the button on the bottom of the right side menu.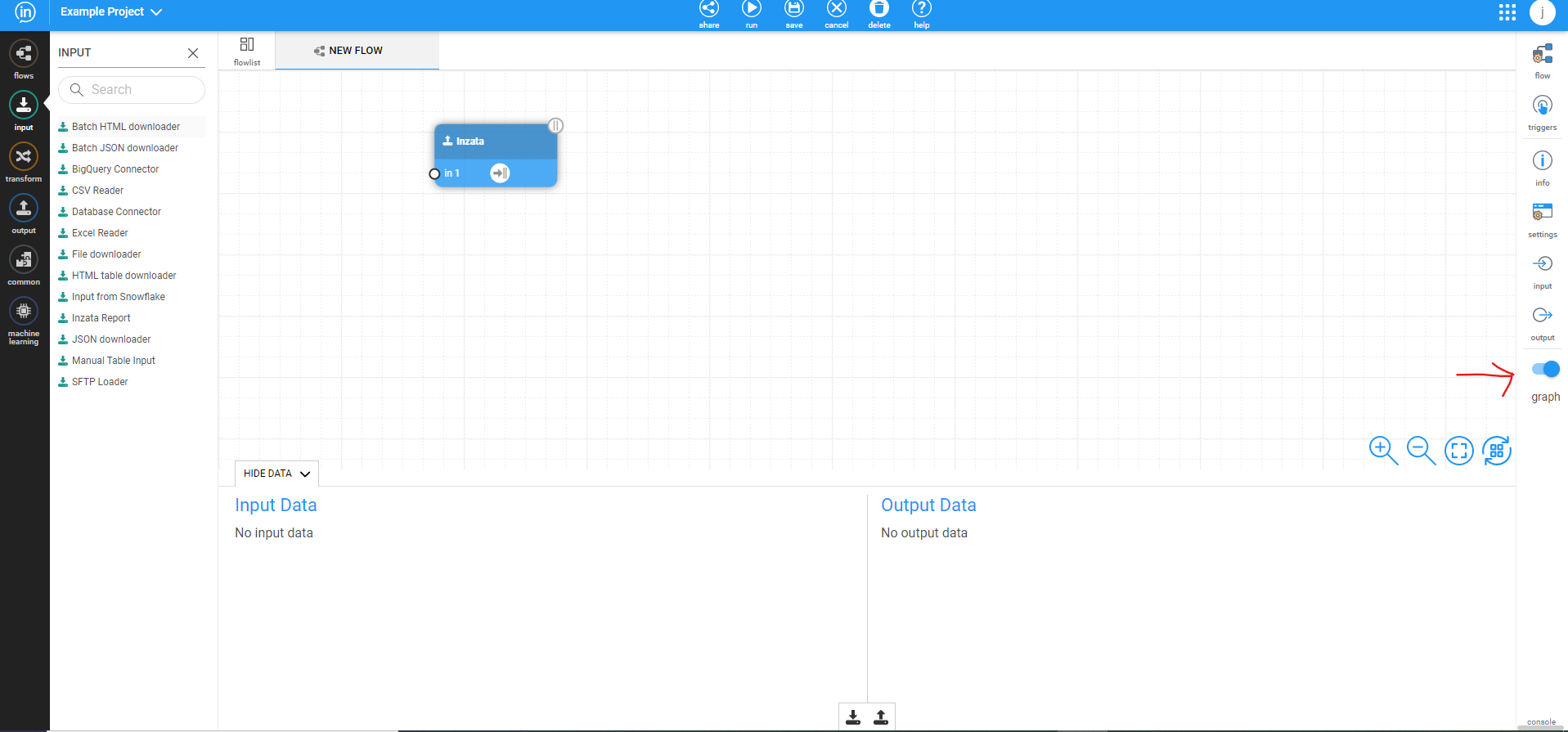
The new view functions similarly to the graph but is easier to see the order of inputs and transformations when you are first starting to work with Inzata. After toggling to a list, you should see the following screen:
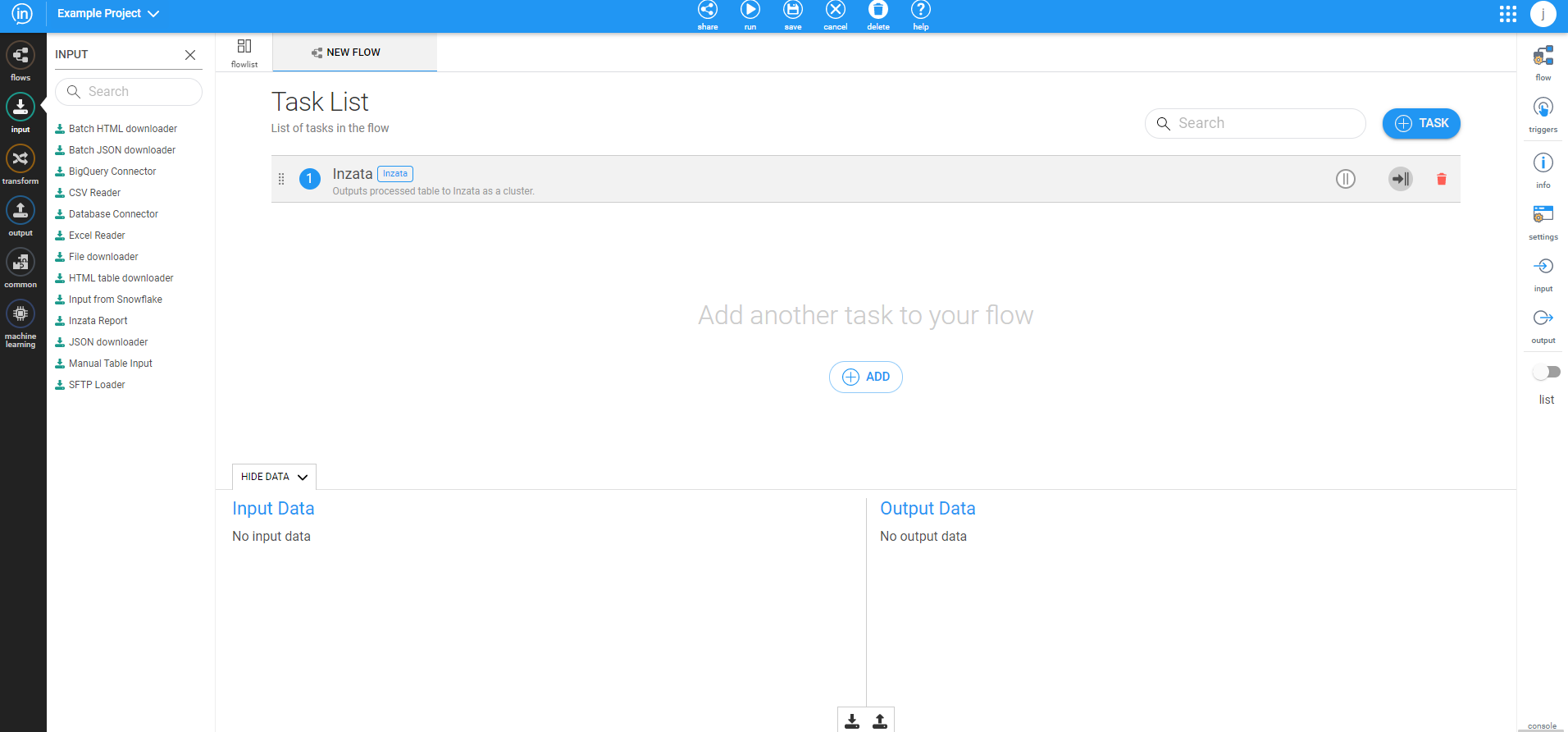
Once your flow is created, you should name it using the options on the far right. Click the top icon “Flow” and enter in a name that will remind you what the data table or information you’re loading will be so you can easily locate it again to make changes if needed.
You should also save your flow periodically as you work to avoid losing any work. The save button is located at the top of the page. After saving, you’ll have to click “Edit” to make any other changes to your flow.
Loading Data from a Source
Now that you have a flow created, you will use the correct input type to start the process of bringing your data into the Inzata platform. The inputs are found on the left of the screen. See this page to view the different input types.
The first thing you will need to do is identify where your data is coming from. The default types of data loads are described below. Click on any of the links to view the specific settings and options for each type of source load.
Batch HTML Downloader
This will bring in batch HTML.
Batch JSON Downloader
This will bring in batch JSON.
BigQuery Connector
This will bring data in from Google BigQuery
CSV Reader
The CSV reader will read in a file in .csv format.
Database Connector
The Database Connector will create a connection to a database to load data into Inzata.
Excel Reader
The Excel Reader will read in a file in .xls and .xlsx format.
File Downloader
The File Downloader is for downloading a file from a web source into Inzata.
HTML Table Downloader
The HTML Table Downloader enables you to scrape web data.
Inzata Report
The Inzata Report box operates off data that is already loaded into Inzata.
JSON Downloader
The JSON downloader will pull data in a JSON format.
Manual Table Input
Use the Manual Table Input to copy and paste a table to load into Inzata.
SFTP Loader
The SFTP loader will load data that are sent to an SFTP.
Once you have determined the type of data you want to load in, simply left-click and drag it into your Task List above the blue “Inzata” already there. In this example, a CSV file will be uploaded (Excel Reader will work similarly). Notice there is now a green “CSV Reader” line in the list.
When you select that, a menu will appear on the right of the screen. (You may need to click on Settings to toggle the menu open.)
Click the blue UPLOAD button which will open your folders for you to select a file to upload. If “Mutiload” is selected, you can upload multiple files at once but you will still only be able to connect to a single CSV file in this Flow.
Once your file is uploaded, click on it in the list so that its name appears in the “File selected” box.
While not required, it is suggested to click the box next to “Use Safe Mode” which just strips out any residual formatting from the source file as it’s uploaded into Inzata.
Using the “Output data” to preview your data
After you have your file selected, you can click the arrow button at the far right of the input data (in this case CSV Reader) to run the flow up to that point.
Once you click that, it will show a preview of your data in the bottom right under the “Output Data” header. This will allow you to check that the data coming in is in the expected format and give a visual representation as you start to add transformations to your data.
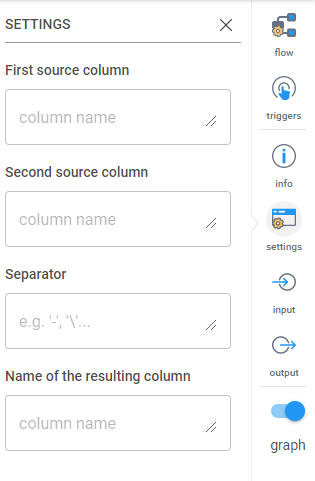
Common Transformations and When to Use Them
Now that you have a file selected to upload, you can use Inzata’s built-in transformations to set up cleaning procedures to improve data quality as it’s brought into the Inzata system. The transformations are found on the left of the screen by clicking on the yellow icon with “transform” under it. See this page to view the different transformation types.
Several transformations are commonly used as best practices:
- Date Converter: While in rare cases dates are standardized throughout a file, Inzata recommends using the Date Converter transformation to ensure all dates read in the same format.
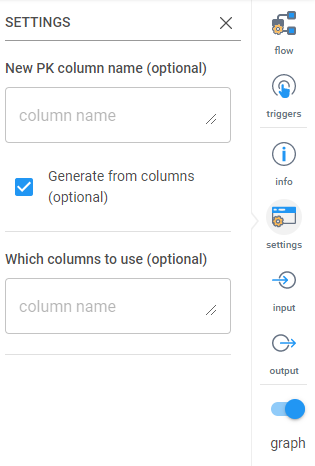
- Primary Key: If there is no primary key on the table, this transformation will create one. Simply enter the name of the primary key column (ex. “pkgen”) and Inzata will create a primary key column. If you would like the Primary Key to be derived from existing columns (ex. First Name, Last Name, Transaction Date), select the “Generate from columns” and enter in the names of the columns in the “Which Columns to Use” box. Make sure to separate the column names with a comma.
- Prefix/Suffix Column: When loading in data from multiple tables, the chance of repeating column headers increases. To avoid confusion as you’re building your report, it is recommended to add an identifying prefix to each column header. To add the prefix to every column, leave the “Column Name” box blank. (Ex. If you’re loading in a table of Customers, add “cust_” in the Prefix box and select “use on header”.) This is typically the last transformation applied so no new columns are created without the Prefix added.
Loading the Data
Once your data source is connected to and the transformations are applied, you are ready to load your data into Inzata. Click on the Inzata Load icon to open the settings on the right. It will give you the option to name your cluster by typing a name in the box under “Cluster”. Creating a name here will make it easier in the inModeler application but is not necessary.
Make sure you save your Flow and then click the “Run” button along the top of the flow near the “Save” and “Edit” buttons. Upon successfully running, you should see green boxes on each piece of the flow. Click the “Open Data Integration” on the Inzata Load to go to the next step of loading data.
To get started with inModeler and what happens after running a data load, click here.

